在二十世纪七十年代以前,金融机构主要采用专家制度法、五级分类法等来对信用风险进行评估;后来建立了基于财务指标的信贷评分模型,在此阶段,信用风险度量方法主要以定性分析为和主观判断为主。20世纪90年代以 ...
在二十世纪七十年代以前,金融机构主要采用专家制度法、五级分类法等来对信用风险进行评估;后来建立了基于财务指标的信贷评分模型,在此阶段,信用风险度量方法主要以定性分析为和主观判断为主。20世纪90年代以后,西方金融机构在上述信用风险度量方法的基础上开始探索新的、更为精确的信用风险度量模型,如Credit Metrics模型、KMV模型等。因此,根据其度量方法的不同,可将其分为两类:古典信用风险度量方法(20世纪90年代以前)和现代信用风险度量模型(20世纪90年代以后)。
一、传统信用风险度量技术
1、国外研究现状
美国纽约大学教授Edwand Altman(1968)在Beaver(1966)开创性研究的基础上,采用判别分析技术方法,建立了一个5变量的第一代Z评分模型[1]。Altman、Narayanan和Haldeman(1977)设计了7变量的第二代Z评分模型,并在Altman不断完善的基础上,该方法已成为一种较为实用的信用风险分析工具,可用于上市公司、非上市公司的信用风险评估。Aziz等(1989)对三大模型(第一代Z评分模型、第二代Z评分模型和现金流量模型)在预测企业违约时的预测结果进行分析,研究结果表明现金流量模型的精确率高于第一代Z评分模型和第二代Z评分模型预测效果的精确率。Kim等(2007)运用Z评分模型,以美国1996-2001年间破产公司为样本,对其进行实证分析,研究结果表明Z评分模型对服务业、制造业和零售业的企业破产有较强的预测能力,且企业破产的预测准确率随着预测期限的增加而呈现呈下降趋势。Z评分模型和Zeta模型所提供的风险评估方法成本低,简单易行,可操作性性强;但假设条件严格,理论基础较为薄弱。
Berkson(1944)首次建立了Logit模型,Ohlson(1980)首次将该模型用于预测公司财务危机。Ohlson(1980)通过构建一个多元Logistic违约率模型(该模型含有9个变量)来对其预测能力进行实证分析,研究结果表明该模型的准确率高达92%以上。Zavgren(1985)运用Logistic模型对破产企业与非破产企业样本之间的配比问题进行研究,认为1:2的配比效果比1:1要好。Theofanis(1987)提出了确定Logistic模型最优分界点的公式。Logit模型的出现弥补了判别分析法假设条件严格的缺陷,是信用风险度量史上的一大进步,但自身也是建立在一定的假设基础之上,存在一定的缺陷,需要进一步探讨研究新的信用风险度量方法。除了以上介绍的信用风险分析方法以外,还有回归分析法、人工智能法等。
古典信用风险的度量方法,如专家制度法、信用评级法以及信用评分模型等,它们对信用风险度量的结果都在一定基础上依赖于专家打分,主观随意性较强,大都属于定性分析。因此,专家学者们在此基础上开始探索新的、更精确的信用风险度量模型。
2、国内研究现状
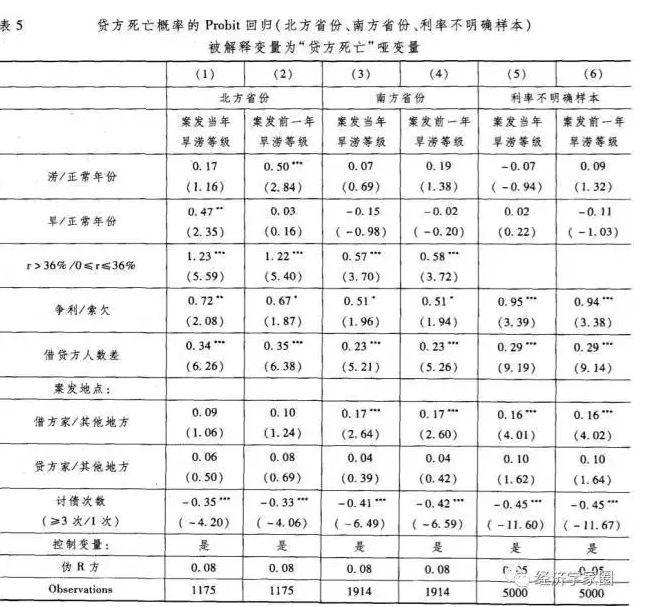
张维和李玉霜(1998)对传统Logit模型、判别信用分析模型和基于现代计算机技术和人工智能的神经网络法、专家系统法等信用风险分析方法进行系统地综述,并对上述信用风险分析方法的未来发展进行一定的展望。石晓军、张振霞(2001)系统地阐述了现代信用风险度量技术和古典信用分析方法的基本原理和异同,对我国商业银行应具体采用哪种信用风险度量方法具有一定的指导意义。王春峰、张维和万海晖(1998)分析我国某商业银行贷款偿还情况时,采用两种信用风险度量方法即Logit模型和多元判别分析法进行实证分析,研究结果证实了信用判别分析方法的有效性,且结果也表明Logit模型信用风险预测能力的精确性要高于判别分析法的精确性。张维、王春峰和万海晖(1999)在对商业银行信用风险的大小进行度量时,采用了两种信用风险度量方法:判别分析法和神经网络法,结果表明神经网络法的预测精确度比判别分析法更高。曾勇和方洪全(2004)对估计样本建立4个风险等级的Logit回归模型和线性判别模型进行实证分析,研究结果表明Logit模型和线性判别模型对样本信用风险的预测能力都较强。任若恩、石晓军和肖远文(2005)采用Logit模型对比较设计的15种典型的样本配比-临界点进行实证分析,发现1:1的样本配比与我国实际情况吻合度较低,0.647的临界点和1:3的样本配比与我国实际情况吻合度较高。
综上述,我国学者对古典信用风险度量技术进行了一系列研究,但实际上,我国学者对线性判别模型、Logistic模型等研究层面较浅,在研究过程中简单化违约率和财务指标之间的关系,但实际上违约率与不同财务指标之间的关系是复杂多样的(Moody公司研究结果表明),因而与现实存在一定程度上的背离。
3、古典信用风险度量方法的评述
古典信用风险的度量方法,如专家制度法、信用评级法以及信用评分模型等,它们对信用风险度量的结果都在一定基础上依赖于专家打分,主观随意性较强。专家制度法需要大量的信用分析专家来维持,分析结果受专家自身素质高低和经验丰富程度的直接影响,对于一些难以量化的指标,在打分标准上难以做到统一,使得分析结果不稳定,且存在使用成本昂贵的问题。信用评级法同样存在以上问题,如缺乏客观的统一尺度,评级机构对市场反应较为缓慢等。信用评分模型以会计账面价值为基础,会计数据不能像资本市场数据和价值一样反映公司经营状况中快速、细微的变化,难以全面反映公司的经营状况和前景,使得该模型的应用范围受到一定程度上的限制;由于现实经济现象本就是非线性的,从而该模型在假定解释变量之间、解释变量和自变量之间均存在线性关系的基础上对现实的预测结果难以精确。此外,神经网络、CASA的神经网络模型、专家系统、死亡率模型等古典信用风险度量方法也都存在不可忽视的一系列缺陷,因此,专家学者们在此基础上开始探索新的、更精确的信用风险度量模型。
古典信用风险度量方法虽然有不可避免的一系列缺点,但其在头寸限制、判断、管理手段、经验以及例外程序等方面,在一些方面仍然起着极其重要的作用,因此,古典信用风险度量方法在实践中仍具有较高的应用价值。
二、现代信用风险度量技术
1、国外研究现状
1993年,著名的风险管理公司Kealhofer、Mcquown和Vasicek(KMV)公司以BSM模型为理论基础,推出了基于股票市场度量信用风险的违约预测模型。Sean C.Keenan、Roger M.Stein&Jorge R.Sobehart(2000)第一次公布了一套验证KMV模型有效性的技术方法,研究结果表明该模型预测风险的准确率最高,且发生一类错误和二类错误的概率相对较小。IrinaKorablev、Kurbat&Matthew(2002)使用校对和水平确认的方法对KMV模型的有效性进行了实证检验,研究结果证实KMV模型是有效地,并且预测结果与样本公司资产相关性、样本规模等因素紧密相关[10]。JeffBohn&PeterCrodhie(2003)采用KMV模型专门对金融类公司的违约预测能力进行分析,研究结果显KMV模型能够很好地对金融类公司信用质量的变化作出准确地预测。KMV模型对上市公司违约风险有较好的预测能力,但该模型主要用于度量上市公司的信用风险,对非上市公司或中小企业的应用受到一定程度的限制,且该模型的预期违约概率的经验计算法以大量的违约数据库为基础,但在一般情况下该违约数据库并不容易获取。
J.P。摩根等机构于1997年4月研制出一种新的信用风险度量方法,该方法以大量历史数据和VAR方法为基础,来确定未来信用资产组合价值的变化和整个信用资产组合风险敞口的大小,这种新的度量信用风险的方法就是CreditMetrics模型。JonesandMingo(1999),Kpmecpeat& Forest(2000)对CreditMetrics模型作了进一步拓展。该模型是一种盯市模型,适用范围较广。但该模型只是提供了信用组合分散化思想的整体框架,但其本身并没有回答关于风险的基本建模及定价问题,且该模型忽略了宏观经济因素,这与当前的信用风险管理存在一定程度上的背离。
瑞士信贷金融产品公司于1996年开发了一种新的的基于保险学精算的信用风险度量模型,这种新的信用风险度量模型就是CreditRisk+模型。CreditRisk+模型就是在Bayes Risk(贝叶斯风险)定义框架下,在违约资产的风险敞口和违约可能性已知的情况下,给出违约损失的分布;且该模型认为,违约与市场风险与降级风险无关,因此CreditRisk+模型只考虑两种状态:违约或不违约。在CreditRisk+模型中,所需估计变量很少,计算较为简便,但该模型忽略市场风险和信用评级的转移风险,没有考虑到债务人信用等级变化的影响,且没有涉及非线性产品,如掉期、期货、如远期合约、期权等。
麦肯锡公司在1998年根据计量经济学原理和基本动力学理论提出一个基于经济学的多因子模型,即CreditPortfolioView模型,它是CreditMetrics模型的扩展和补充。CreditPortfolioView模型通过对宏观经济条件(GDP增长率、失业率、储蓄率、汇率、利率以及政府储备等)的不同取值,模拟联合迁移概率和联合违约概率在不同国家、不同行业、不同信用评级集团下的取值,得到这样一个结论:当经济繁荣时,降级事件减少,违约事件减少;当经济衰退时,降级事件增多,违约事件增多。该模型采用宏观经济学的方法,把企业违约率和联合转移率与GDP率、失业率等宏观经济因素相联系,但该模型需要大量的数据,数据获取比较困难,且成本较高。
KPMG公司(1998),Mark&Crouhy(1998)和Belkin(1998a-d)在借鉴Pliska&Harrison(1981),Wilner&Ginzberg&Maloney(1994)等人研究的风险中性成果的基础上提出贷款分析系统(LAS)[14],Geske& Delianedias(1998)利用期权定价理论对该模型做了进一步拓展。
2、国内研究现状
石晓军、张振霞(2001)系统地阐述了信用风险度量技术的演进和现代信用风险度量模型的理论基础,有利于推动我国商业银行信用风险度量技术的进步。沈沛龙和任若恩(2002)比较分析了信用度量术模型、信用组合观点模型、贷款分析系统和风险附加模型的理论基础和研究方法,并系统地阐述了上述模型之间的异同[15]。詹元瑞(2004)、孟庆福(2006)全面系统地介绍了信用度量术模型、信用组合观点模型、风险附加模型和KMV模型的理论基础和各自的优缺点。李家军(2006)对信用度量术模型、信用组合观点模型、风险附加模型和KMV模型的理论基础和各自的优缺点进行了比较分析,将博弈理论引入主观信用风险控制过程中,建立博弈模型,使银企选择对双方都有利的策略,有效控制主观信用风险。叶蜀君(2008)在分析比较现代信用风险度量主流模型的基础上,将突变理论引入企业信用风险度量技术之中,研究结果表明引入突变理论后的数理模型能够更有效地度量和控制信用风险。
陈殿左和石晓军(2004)采用默顿模型对我国72家上市公司信用风险与资产波动、债权结构的关系进行实证分析,研究结果表明信用风险与债权结构有较大关系,但与资产波动的关系没有得到实证支持。张玲、杨贞柿和陈收(2004)改进KMV模型中违约点设定和股权市值的计算方法,运用改进后的KMV模型来实证检验上市公司信用风险的大小,结果表明该模型识别信用风险的效果较好。翟东升(2007)采用KMV模型对沪深两市15家ST的公司和15家非ST的公司进行实证分析,研究结果表明,在违约前三年ST公司和非ST公司的违约距离没有明显的差异,在违约前两年ST公司与和非ST公司的违约距离之间的差异变大,非ST公司且的违约距离均值比ST公司的违约距离均值要明显偏高。杨永生和周子元(2008)对我国信用风险计量研究中存在的问题进行了系统地阐述,并对RiskCalc模型、KMV模型提出了改进措施。周春生(微博)和王志诚(2006)系统地综述了金融风险研究进展的国际文献,对公司使用衍生工具进行风险管理的原因从地区差异、税收影响、公司治理结构、财务危机、信息不对称和管理层的风险偏好等六个方面进行了详细综述。刘志刚(2008)将信用风险引入到经济周期研究领域,研究经济周期与信用风险、回收率和违约率的相关关系,研究结果表明经济周期等宏观因素对信用风险、违约率和回收率均具有较强的影响力和解释力。
综上述,我国学者对现代信用风险度量技术做了一系列研究,并取得了相应的成果,但也存在一些问题,如关于结构模型、研究框架等比较局限;由于企业违约数据不对外公布,无法建立健全的长期历史违约数据库,使得研究成果至今仍停留在违约距离层面,难以建立起违约距离与预期违约率之间的映射关系等。
三、现代信用风险度量模型在我国银行业的适用性分析
CreditMetrics模型、Credit Risk+模型、Credit Portfocio View模型、KMV模型等信用风险度量模型在欧美等发达国家的国际银行中得到广泛应用,并在信用风险度量方面取得较好成效。但由于各模型的建模基础与应用环境不同,信用风险度量模型在对欧美等发达国家之外的银行和债务人进行信用风险评估时,其效果并不太理想。同样,Credit Metrics模型、Credit Risk+模型、Credit Portfocio View模型等信用风险度量模型受模型假定与应用环境的限制在我国的适应性也不是很强, KMV模型在理论模型与应用环境上与我国的经济环境还相对而言较为吻合,因此,在我国商业银行信用风险度量领域的适应性较高。
CreditMetrics模型框架中融合了违约率、违约相关性、违约回收率、信用等级等相关指标,并引入风险价值法,因此该模型能够使我国商业银行对准备金与商业银行经济资本水平的衡量更加精确。但该模型在度量信用风险的过程中对国家和行业提供的长期违约历史数据和评级公司提供的信用评级的依赖性很高,对于我国这样一个经济转轨型国家来说,商业银行对信用风险度量的发展较晚,国家和行业的长期历史数据库不够完整,信用评级系统尚不够完善,还不具备Credit Metrics模型在我国商业银行信用风险管理领域应用的实践条件,因此,当前Credit Metrics模型在我国商业银行信用风险管理领域还缺乏一定的实践性和可行性。
对于Credit Risk+模型,重庆大学戴思瑞教授研究表明:Credit Risk+模型对贷款组合模型预测能力较好,但对单笔贷款的预测结果不够准确,与实际情况存在较大的差距;借款人信用等级对经济配置比例产生很大影响,不同的信用等级的经济资本的配置比例产生较大的差异;在统计方面,独立性的假设条件(PD、LGD)难以满足,它们之间存在正相关关系。因此,Credit Risk+模型在我国商业银行信用风险管理领域还缺乏一定的实践性和可行性。
CreditPortfocio View模型考虑了宏观因素(GDP增长率、失业率、储蓄率、汇率、利率以及政府储备等)对信用评级转移的影响,可以很好地刻画回收率的不确定性,但难以确定信用级别转移与宏观经济因素之间的具体函数、宏观经济因素的经济含义以及个数等,使得该模型的结果缺乏相对的稳定性。因此,Credit Portfocio View模型在我国的应用前景不大。
KMV模型侧重于预测公司未来违约概率,强调重点是公司本身的特征。该模型基于股票市场的实时行情,在度量信用风险的过程之中纳入市场信息,采用企业股票市场价格分析法,及时更新输入数据,计算出动态的企业预期违约概率,便于我国商业银行更好地做好信用风险度量和管理工作。KMV模型建立在发达的资本市场基础之上,虽然我国的资本市场起步较晚,证券市场发展不完善,存在股权分裂中的非流通股定价问题,但董颖颖、薛峰、关伟(2004)、陈志武(微博)博士等研究发现,可以得出非流通股价格和流通股价格、非流通股价格和每股净资产之间的线性关系,因而这一难题目前已得到部分性解决;虽然我国现在的违约历史数据库还不够完善,尚无法通过建立预期违约概率与违约距离之间的映射函数式来求出经验预期违约概率,但可以根据KMV模型的一系列假设,求出理论上的预期违约概率(EDF)。加之我国当前资本市场发展迅速,上市公司披露的数据信息越来越规范化、透明化、完整化,KMV模型在我国商业银行信用风险度量与管理领域具有较好的适用性,并且具有广泛的应用前景。
四、结论
从上文分析可以看出,国内外学者对传统信用风险度量方法与现代信用风险度量方法进行了一系列研究,并取得了相应的成果,但也存在一些问题,如关于结构模型、研究框架比较局限等。我国在商业银行信用风险度量和管理方面的研究起步较晚,至今尚未形成一套较为完善的信用风险度量与管理体系,定量分析涉及较少,缺乏对信用风险度量与管理的系统研究。本文通过对信用风险度量技术(古典信用风险度量方法和现代信用风险度量模型)的比较分析与归纳,找出其在度量理论与实践方面存在的不足,并在此基础上指出KMV模型是比较适用于我国的信用风险度量模型,并展开深入分析。这一关于信用风险量化的理论研究有助于完善商业银行信用风险度量和管理的理论基础,同时呼吁需要对信用风险度量做更深层次的理论研究。
通过对现代信用风险度量模型在我国银行业的适用性进行分析,KMV模型在我国商业银行信用风险度量与管理领域的适用性较好,并且具有广泛的应用前景。因此,我国需要引入现代信用风险度量技术,并结合我国实际情况进行一定的修正,来对其信用风险进行量化分析,以此来提高我国商业银行度量和管理信用风险的技术水平和资本使用效率等,加强对信用风险的早期预警和防范。










监督方式防骗必读生意骗场亲历故事维权律师专家提醒诚信红榜失信黑榜工商公告税务公告法院公告官渡法院公告
个人信用企业信用政府信用网站信用理论研究政策研究技术研究市场研究信用评级国际评级机构资信调查财产保全担保商帐催收征信授信信用管理培训
华北地区山东山西内蒙古河北天津北京华东地区江苏浙江安徽上海华南地区广西海南福建广东华中地区江西湖南河南湖北东北地区吉林黑龙江辽宁西北地区青海宁夏甘肃新疆陕西西南地区西藏贵州云南四川重庆
